We build digital products
Ideation
Innovation
Implementation
What We Do
Software Engineering
Data Engineering
Architecture & Concept
Bootstrap Teams
Consulting
Prototyping
GDPR Compliance
Cloud Migration
Cloud Native Development
Microservices
Performance Optimization
Analytics
How We Work
Continuous Everything
We deliver production-ready, usable software in short intervals creating fast-feedback loops and maximum transparency.
You should use iterative development only on projects that you want to succeed.
Evidence-Based
Measure what matters, and draw conclusions from data, that is how to continuously improve.
Information is the oil of the 21st century, and analytics is the combustion engine.
Simplicity
Build just enough to add value, deliver it to the user, get feedback, and repeat. Do this as often as possible.
Simplicity carried to the extreme becomes elegance.
Sustainability
We build projects for the long run. Quality conscious processes and methods, like Automated Testing and Static Code Analysis go without question.
The only way to go fast, is to go well.
Our Toolbox
All Platforms
We build applications for all platforms.
Web
iOS
Android
Hybrid
APIs
Years of experience implementing reusable APIs that work for all platforms.
HTTP
REST
gRPC
GraphQL
API Orchestration
Search
We make unstructured data discoverable.
Elasticsearch
Solr
Lucene
Machine Learning / AI
Broad expertise with production ready machine learning algorithms.
Categorization
Prediction
Deep Learning
Sentiment Analysis
Cloud Technologies
Set up secure cloud environments for critical data.
GCP, AWS, Azure...
Multicloud
Kubernetes
Docker
Big Data
Well-versed with handling of large amounts of data.
Clustering
Automatic Scaling
Data Mining
Stream Processing
Lambda Architecture
We came up with the idea for Erste Group's online banking platform George and evolved it from a prototype to a banking platform for millions of people around Europe.
Together with BeeOne, now George-Labs, and Erste Group we developed and launched George — Europe’s most exceptional online banking platform — to millions of demanding customers. George is immense in all directions: from data protection and security considerations, over peak load times to data processing throughput during (quarterly/yearly) closing of accounts.
George combines up to date technology with a progressive, cross-functional, team on top of stable and proven Software. Together we went from no team to a team of several hundred people.

We teamed up with Mostly AI, the hottest data crunching company in our area, to launch a cloud native Demo of their GENERATE solution.
We took over the customer-facing part of the offering, ensuring performance, a convenient user interface, and security.
Mostly AI uses state-of-the art machine learning techniques to synthesize privacy-critical data, which is now available at your fingertips through the SaaS solution we built together.


Together with ÖBB-BCC and Schramm Öhler Attorneys, we implemented an application that increases the efficiency of tendering procedures.
The software enables an administrator to assemble forms using a simple user interface and to connect each form with an uploaded MS Word-file containing placeholders. Users can then fill out these forms to retrieve dynamically generates MS Word-files as a starting point for their work.
Alles Clara is a platform to help people caring for a friend, a relative, a partner. With Alles Clara, we bring together professional consultants from various disciplines (care, psychology, community work) to help those who help.
Alles Clara is a real-time chat solution enhanced with tools and wizards to make the consultation fast and friction-less. We partnered up with TwoNext to provide a great technical foundation and kick-start the project as quickly and light-weight as possible.
Most importantly, though, Alles Clara takes extra care to protect the data of the most vulnerable, the patients being cared for. Alles Clara implements an elaborate cryptographic concept to allow communicate freely, safely, without the worry about anyones prying eyes.

With our friends over at Datenwerk, we developed a media-monitoring system, crunching terabytes of unstructured data into analytics, data, and finally insight.
We employ every trick of the trade, with a nice mix of technologies to deliver a cost-effective and scalable system to track and analyze public opinion about just about anything.
Together with TwoNext, Vienna’s leading digital-social/social-digital inclusion hub, we worked hard to get the benefits of high-tech to the people who need help the most.
We enable NGOs to enter digital product development, and stand in to transfer targeted know-how for autonomous development in the future. The list of participants include Austrian charities like Caritas, Volkshilfe, and Lebenshilfe, but also international ones like Narko-Ne from Bosnia and Herzegovina.
Besides that, we teamed up with TwoNext to improve the situation of caregivers in Austria and the DACH region, going from concept, verification, and development to full rollout and business development.
Together with our friends at Viable, we planned and implemented Raiffeisen Bausparkasse's new Online Wohnfinanzierung.
The online flow allows mortgage seekers to apply for their mortgages fully digital, without ever visiting a branch. Advisors are always available via chat and video calls for individual requests and support throughout the user journey.
With our experience in quality Software Engineering and FinTech, we laid a solid foundation for the product. But we didn’t stop there, and grew the product based on customer feedback in an agile manner.
In the end, we didn't just improve the customer satisfaction, but also integrated a modern API architecture into a complex digital landscape.
We helped GitLab to lower the cost and improve the performance and quality of their code search.
We identified tweaks to reduce the size of their search indices and to improve the performance and quality of their queries.

Together with Erste Hub, we accelerated the digital transformation of one of the leading banks in the CEE (Central and Eastern Europe) area.
We helped to shape the culture of the digital innovation company, BeeOne, encouraging people to take charge and drive innovation with courageous ideas.
During our time at Erste Hub, we saw hundreds of ideas, prototypes, and even product launches come and go; the most prominent achievement being George.

Our topic extraction, and automated tagging framework, Fabric, helped big media companies such as Kronen Zeitung or Die Presse to optimize and streamline their articles.
Through automated tagging via NLP (Natural Language Processing), we create topic clusters and compile dossier pages for any topic with a significant set of articles.
Automated linking with external sources, like Wikipedia, is also an excellent feature helping journalists to categorize and gather information quickly.

We helped to build and establish friendseek as the largest social network for recreational activities in the german-speaking market.
In collaboration with Synexit, we built a platform that helps to bring people together for recreational activities. They organize in communities and find each other by searching for people having similar interests as themselves.
By now the platform is also known under the names spontacts.com and gemeinsamerleben.com.

Each semester, thousands of students and hundreds of staff members at Zeppelin University used our semantic document management system — Collaboration — to collaborate and coordinate.
Besides basic document management, our Software enriched each entry with extracted data and links articles automatically by topics. A flexible semi-structured cataloging system helped users to find any piece of required information quickly and intuitively.
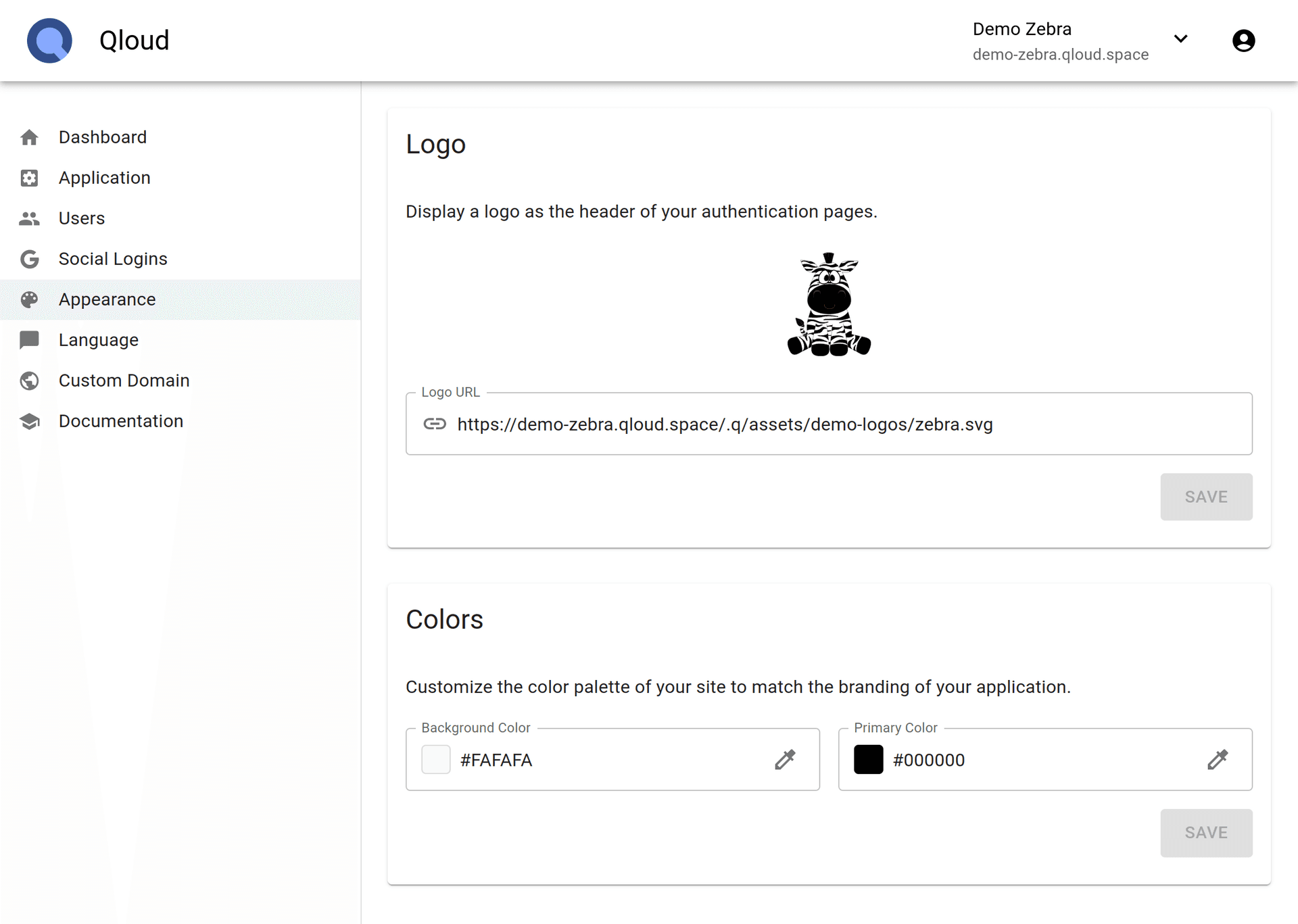
Qloud
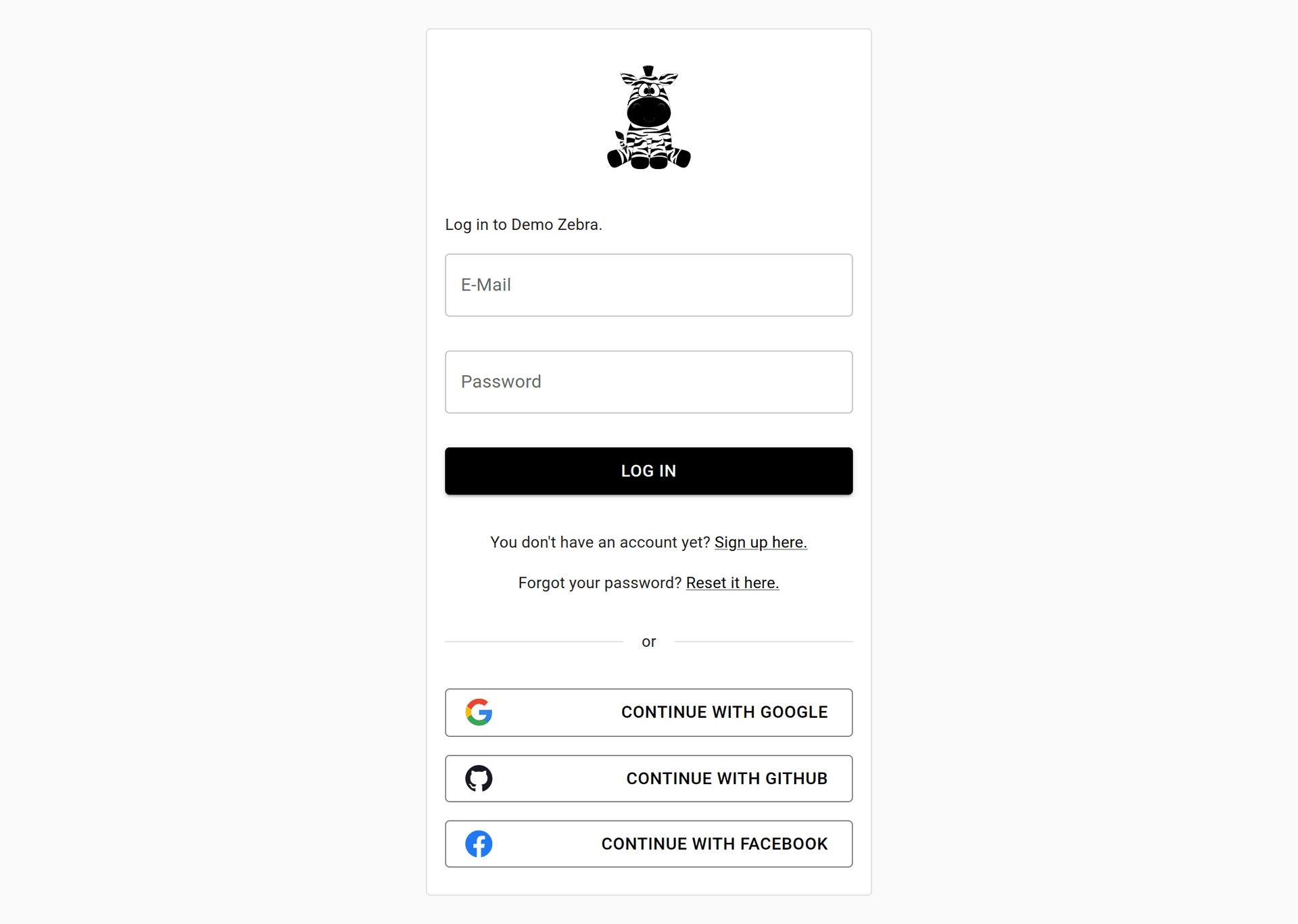
We are the creators of qloud.network. A service that makes it incredibly easy to put an authentication flow in front of any website.
- E-Mail and Password
Plus e-mail verification and password reset flows.
- Third-Party Identity Providers
Such as Google or Facebook.
- Easy as Pie to Integrate
No need to study OAuth 2.0. Just a JSON Web Token to validate.
- Customizable Appearance
Use your own logo and colors.
- User Consent
Link to your Terms of Service and Privacy Policy.
- And a lot more
Custom domains, GDPR-compliant, SSL management, HTTP/2, etc.
Qloud is currently available free of charge as a public beta version. We would love to hear your feedback, so incorporate it into the product and make it your favorite authentication service!
We are a team of experienced IT professionals with different areas of expertise. We have been working together for years, some of us even decades. All of us are capable software developers that do not only ship code, but working products. We are a self-sufficient team, covering every aspect of a Software project — from agile project management to continuous delivery.



You have an idea or a challenge? We are here to help! Drop us a message and let's start a conversation (you can also reach out to us by sending an e-mail to office@semanticlabs.at):